1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| import torch
import numpy as np
import pandas as pd
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class OttoDataset(Dataset):
def __init__(self,filepath,is_train = True,):
xy = pd.read_csv(filepath,skiprows=1)
if is_train:
self.y_data = torch.tensor(pd.factorize(xy.iloc[:,-1])[0],dtype=torch.long)
self.x_data = torch.tensor(xy.iloc[:,1:-1].values,dtype=torch.float32)
else:
self.x_data = torch.tensor(xy.iloc[:,1:].values,dtype=torch.float32)
self.y_data = torch.tensor(xy.iloc[:,0].values,dtype=torch.int)
self.len=len(self.x_data)
def __getitem__(self, item):
return self.x_data[item],self.y_data[item];
def __len__(self):
return self.len
train_dataset = OttoDataset('./data/train.csv')
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle= True,
num_workers=2)
test_dataset = OttoDataset('./data/test.csv',is_train=False)
test_dataloader = DataLoader(dataset=test_dataset,
batch_size=32,
shuffle= False,
num_workers=2)
class NetModel(torch.nn.Module):
def __init__(self):
super(NetModel,self).__init__()
self.l1 = torch.nn.Linear(93,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,9)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self,x):
x = torch.relu(self.l1(x))
x = torch.relu(self.l2(x))
x = torch.relu(self.l3(x))
x = torch.relu(self.l4(x))
x = self.l5(x)
return x
model = NetModel()
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.5)
criterion = torch.nn.CrossEntropyLoss()
epoch_list = []
train_losses = []
def train(epoch):
running_loss = 0.0
for batch_size,data in enumerate(train_dataloader,0):
inputs,labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
average_loss = running_loss / len(train_dataloader)
epoch_list.append(epoch)
train_losses.append(average_loss)
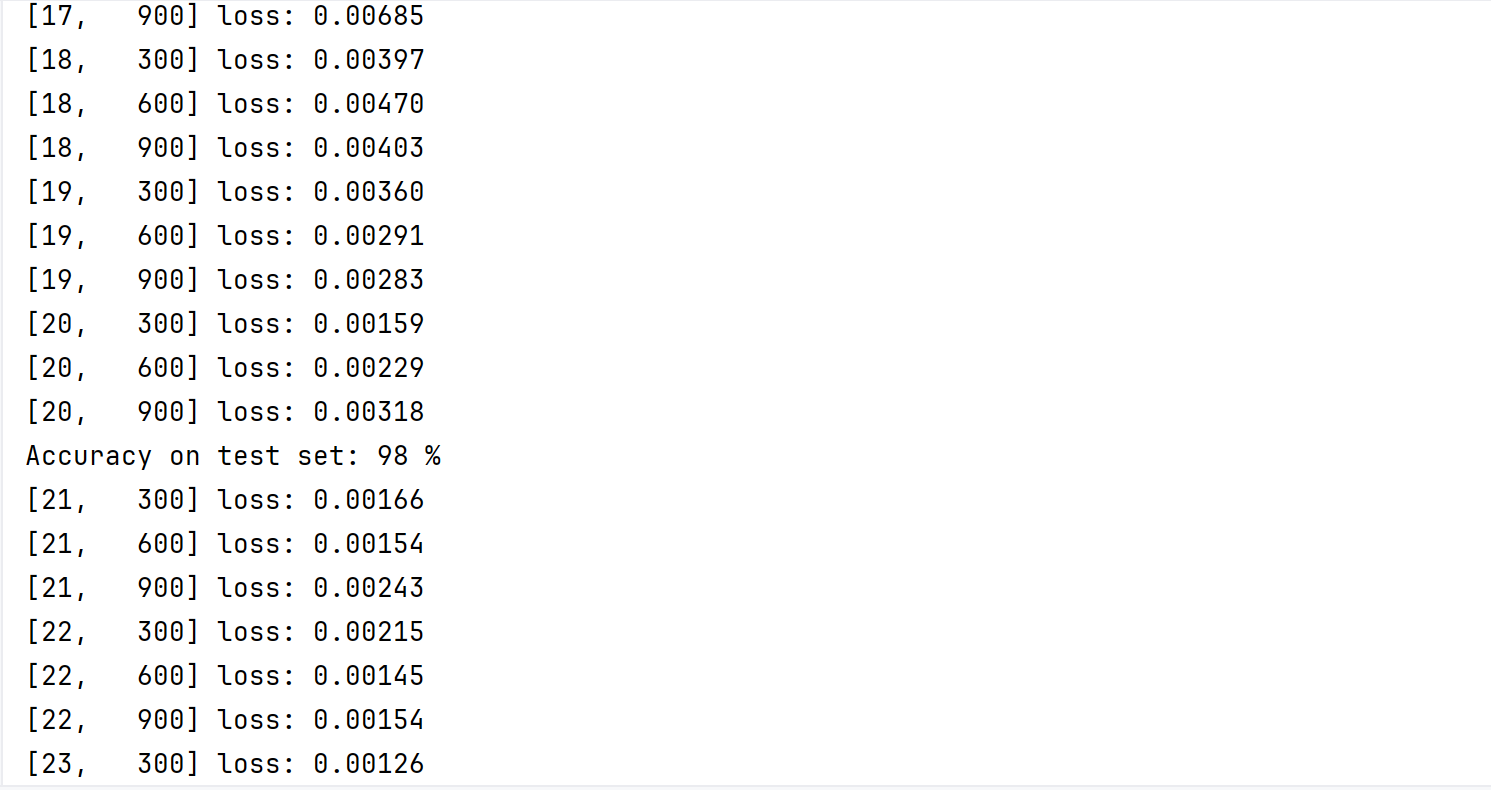
print(f"Epoch [{epoch+1}/50], Loss: {average_loss:.4f}")
def test():
predict_labels = []
with torch.no_grad():
for inputs,ids in test_dataloader:
outputs = torch.softmax(model(inputs), dim=1).numpy()
predict_labels.extend([[id_.item()] + prob.tolist() for id_, prob in zip(ids, outputs)])
df = pd.DataFrame(predict_labels,columns=["id"]+[f"Class_{i}"for i in range(1,10)])
df.to_csv("./data/submission.csv",index=False)
print("Results saved to submission.csv")
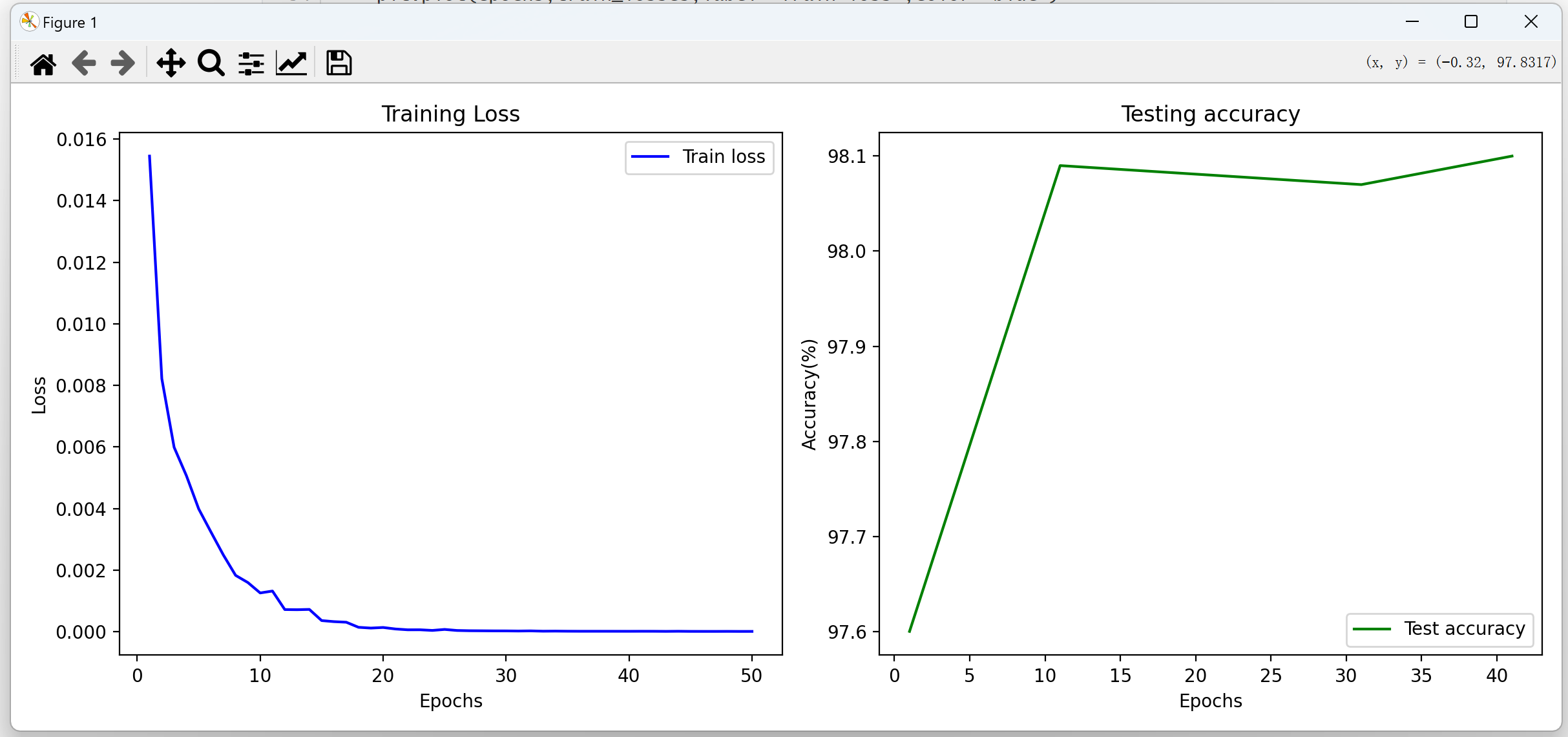
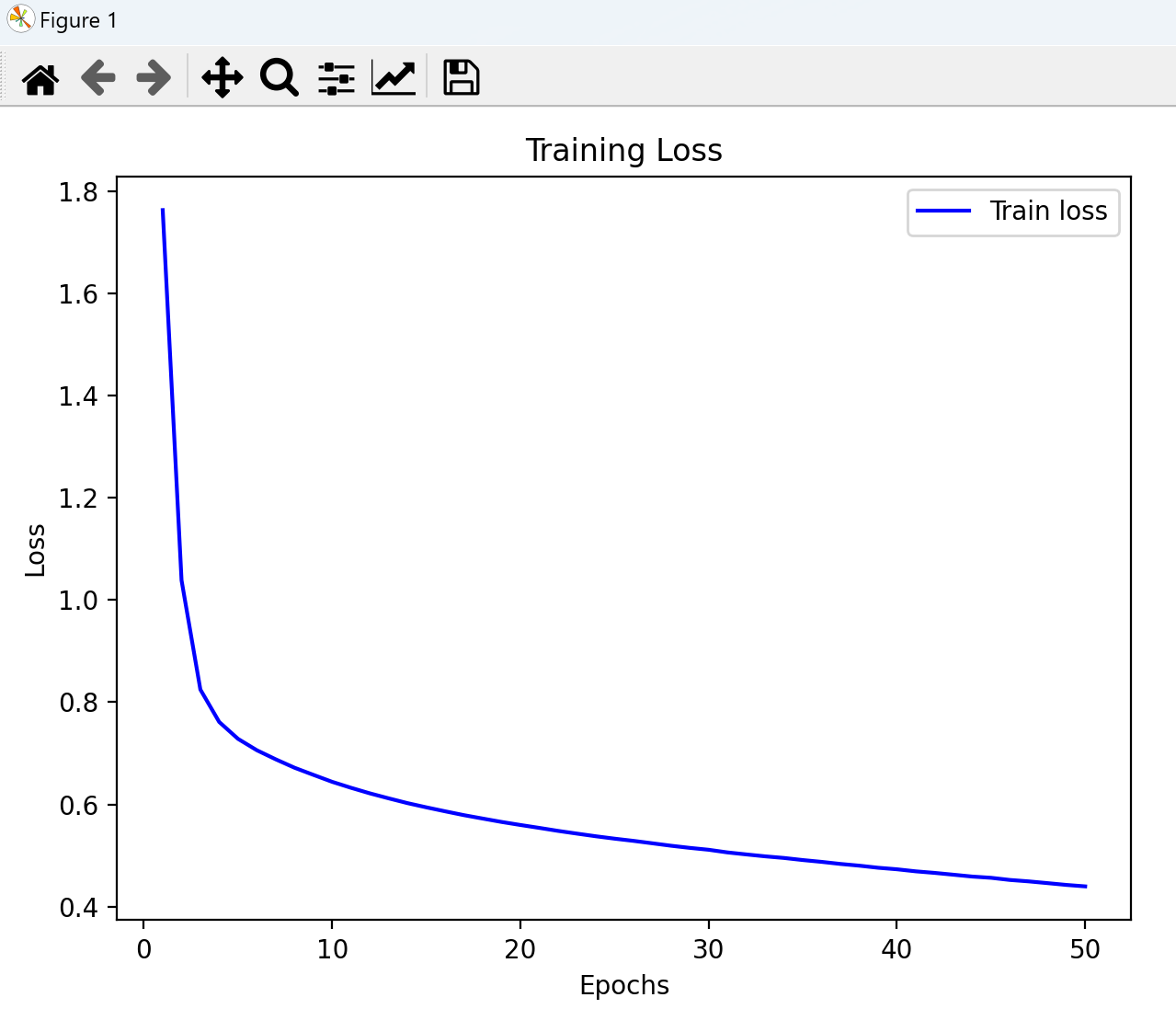
def plot_training():
epochs = range(1,len(train_losses)+1)
plt.figure(figsize=(8,5))
plt.subplot(1,2,1)
plt.plot(epochs,train_losses,label='Train loss',color='blue')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == '__main__':
for epoch in range(50):
train(epoch)
plot_training()
test()
|